What is API Observability

API Observability is a key component to properly execute APIOps Cycles and ensure you’re building something of value for your API users. If you’re not familiar with APIOps Cycles, take a look at this guide which provides an agile framework to quickly build APIs that are business oriented and serve customer needs. API Observability itself is an evolution of traditional monitoring and born out of control systems theory.
Traditional monitoring focuses on tracking known unknowns. This means you already know what to measure like Request Per Second or Errors Per Second. While the metric value may be unknown beforehand, you already know what to measure or probe such as a counter to track requests into buckets. This makes it possible to report on the health of a system (like Red, Yellow, Green), but is a bad tool for troubleshooting engineering or business issues, which usually require asking arbitrary questions.
How can you determine you’re at the limits of traditional monitoring? Well, it’s when you are investigating an issue and you tell your colleague “We could resolve this but we don’t have the right context”. Context is a loaded word, but it means your solution is not able to answer unknown unknowns. Instead, you need to modify the metrics you are tracking, redeploy, and then finally see the result to get that context.
API observability was born out of control systems theory to observe as much as possible the internal workings of a system from its outputs by inferring state and behavior. With a sophisticated analytics tool to analyze all this data, you are able to answer any arbitrary question around your API behavior, not just a few predefined metrics that are directly measurable. This means you are able to answer any question around how your “black box” got into this state or even reproduce that state.

What About the Business-Side?
API Observability is not just used to troubleshoot engineering issues that your API exhibits, it can also help troubleshoot business problems. These may be more abstract in nature, but have the same principles as observing your physical service, but expanding the scope. In order for this to happen, you need full observability into not only the physical infrastructure, but the other inputs as well such as revenue, growth, and sales efficiency metrics. This enables you to expand your “black box” beyond just a service to an entire product or business unit.
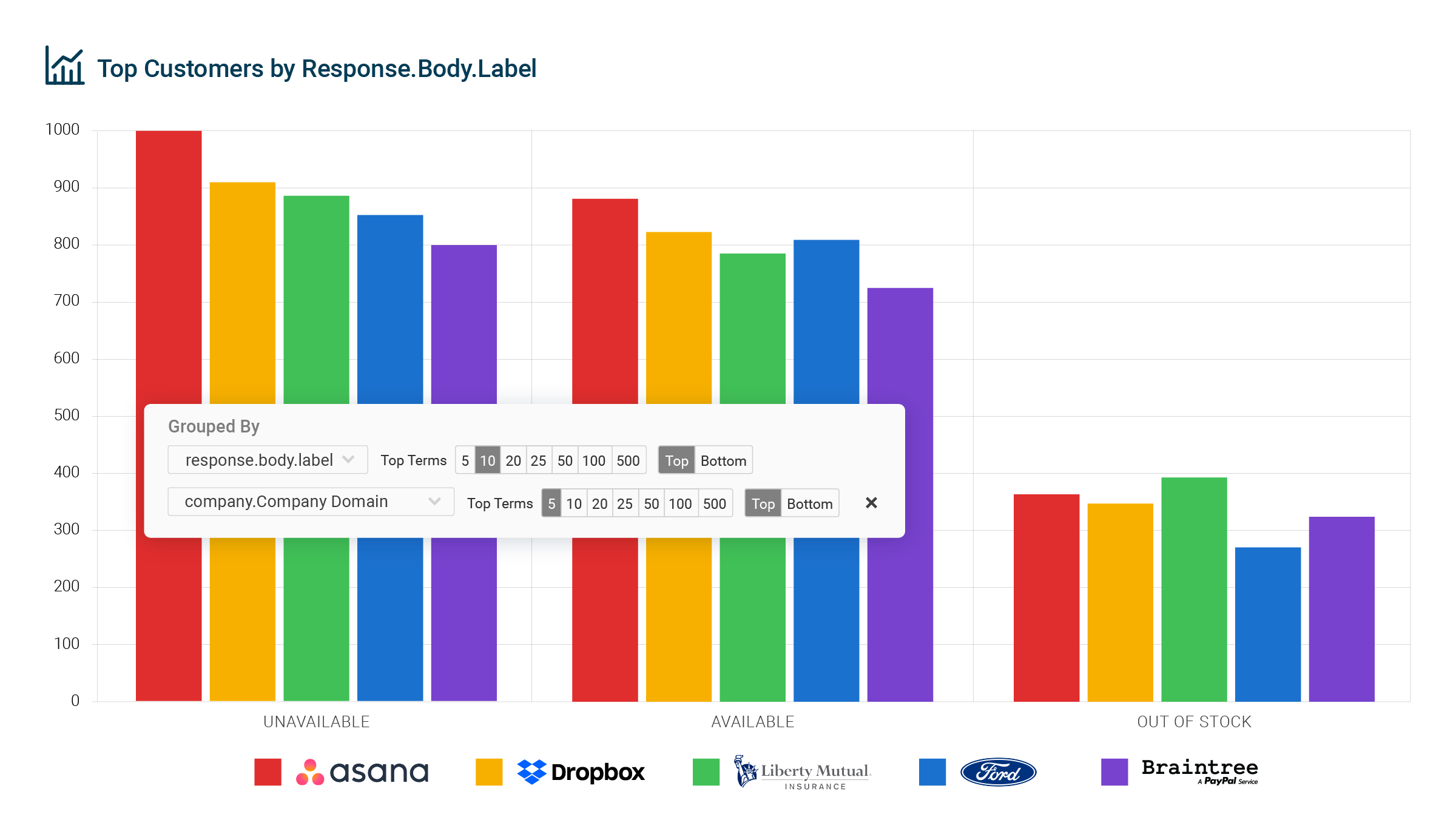
By tying together what happens within your APIs to broader business information like customer demographics, we are now able to answer business questions. For example, we can see which customers have requested items that are out of stock. We do not need to directly have a counter measuring number of out of stock items for each customer. Instead, a high-cardinality, high-dimension analytics system like Moesif is able to track all information flowing out of the API, enabling us to create this report on the fly. In this case, all the information is already available to create an arbitrary report.


Related Articles

API Strategy
Leveraging AI For a Better API Strategy
Learn how to leverage AI to build and fortify your API strategy. Improve design, governance, documentation, and align APIs with business outcomes.
API Strategy
The 5 Best Mixpanel Alternatives of 2025
Learn about the best Mixpanel alternatives to determine the right analytics solution for your use case.

API Development
How to Leverage Moesif Effectively for API Observability
Effectively leverage Moesif for API observability through best practices for integration, event enrichment, custom actions, and engineering workflow integrat...
API Strategy
How to Build an Internal Chargeback Model for Your API and AI Usage Using Moesif
Use Moesif to implement internal chargebacks and enable precise API and AI cost attribution for better transparency and resource optimization.
