The Difference Between Synthetic API Monitoring and API Real User Monitoring
One major concern that all API creators have in common is monitoring.
What is Monitoring?
Monitoring is a way to get insights about our APIs’ health, performance, and usage.
How long does a request take to resolve?
Does the API scale well at peak usage?
Does the rollout of an update lead to problems?
These are just a few of the questions we ask ourselves again and again over the lifecycle of our APIs. We can answer them with a good monitoring setup, but what are the approaches we can take here?
In this article, we going to learn about the two main ways of monitoring and their differences: Synthetic & Real Monitoring
Overall we can say that both approaches form the core of an effective monitoring solution, but let’s find out about each specific approach.
Synthetic Monitoring
The name synthetic monitoring comes from the fact, that this approach uses synthetically generated requests. These requests can be made of 100% generated data or recorded requests made by real clients in the past. The actual monitoring doesn’t happen when a real client sends the request, but when a particular monitoring client sends them. This monitoring client is also responsible for the actual monitoring. It sends the requests and logs how long they take and other information about them.
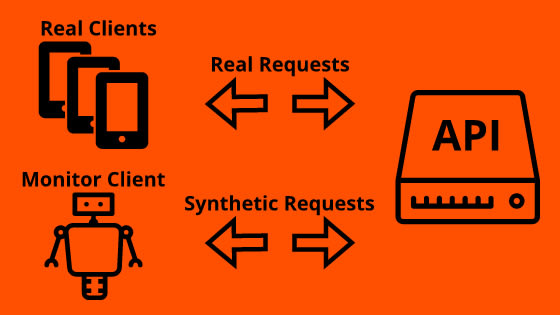
Synthetic monitoring is also known as active monitoring or proactive monitoring, because the monitoring client (pro-)actively sends pings to the API.
One big pro of this approach is that it allows locating problems in the API before they happen to real clients. For example, a developer can create a request that would only be sent to the API in the future when new client versions are out and see what happens.
If the monitoring client runs periodically 24/7, it can also collect data while no real client is online and even before the API is released to actual clients.
The downside of this approach is that it doesn’t allow to see what happens to real clients. It can only test for the things the developers anticipated already or recorded in the past. So the monitoring client could signal perfect API health, but the real client requests could still fail all the time when they behave slightly different than the monitoring client.
Also, generating all possible types of requests can get expensive very quickly, so even if the developers know how to do it, they often can’t create all request types and only create a small collection of tests. Often a test suite may contain only single digit coverage of the entire state space of scenarios. Especially with tools like GraphQL, customers can be more flexible than ever. If you didn’t create a test for the specific customer scenario, you may not know there is an issue at all.
Real User Monitoring
Real User Monitoring, or short RUM, is called that way because it’s monitoring real customer requests rather than relying on synthetic pings. Another name for it is passive monitoring, because there is no active client involved that actively sends requests, but some technology that passively records the requests the clients send. This can be done with hardware solutions like a network TAP, or at the application layer via a tool like Moesif.
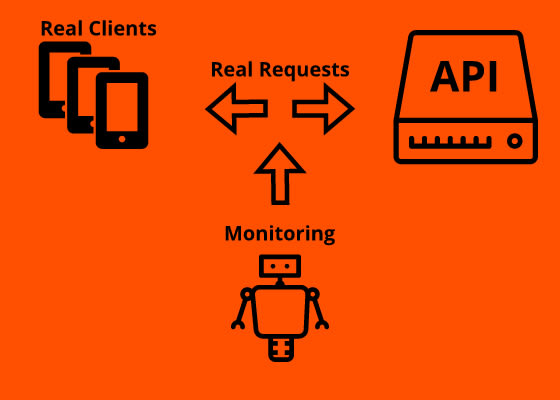
This technique helps with actual client problems that are currently affecting our customers. Even if your synthetic events all show green lights and response with 200 OK, you could still have some customers having troubles. For example, if we actively monitor from the US, but some clients are located in different parts of the world they might get performance degradations that we didn’t anticipate. Real User Monitoring is super helpful for modern dynamic microservice driven applications where API design is constantly in flux. This causes the the test coverage to be too small and not cover every customer scenario.
Since real user monitoring is looking at production traffic, it also helps to replay client behavior of the past for debugging purposes.
The pros of synthetic monitoring are also the cons of real monitoring.
It is only possible to detect problems of real customers when there is traffic. If traffic is meager or if there is no traffic at all, we won’t get any data with real monitoring.
Conclusion
Synthetic and real monitoring techniques have their pros and cons, so a complete monitoring solution should depend on both of these approaches.
They can compensate for each other’s shortcomings and lead to better overall insight.
They even can build on each other. For example, the recorded requests of a real monitoring approach can be used as requests for the synthetic monitoring client. This can be easily done via Moesif’s export to Postman Feature.
excerpt: Accurately Track All API Product Metrics With Moesif


Related Articles

API Strategy
Leveraging AI For a Better API Strategy
Learn how to leverage AI to build and fortify your API strategy. Improve design, governance, documentation, and align APIs with business outcomes.
API Strategy
The 5 Best Mixpanel Alternatives of 2025
Learn about the best Mixpanel alternatives to determine the right analytics solution for your use case.

API Development
How to Leverage Moesif Effectively for API Observability
Effectively leverage Moesif for API observability through best practices for integration, event enrichment, custom actions, and engineering workflow integrat...
API Strategy
How to Build an Internal Chargeback Model for Your API and AI Usage Using Moesif
Use Moesif to implement internal chargebacks and enable precise API and AI cost attribution for better transparency and resource optimization.