13 API Metrics That Every Platform Team Should be Tracking
Identifying key API metrics
Each team needs to track different KPIs when it comes to APIs. Different teams within an organization can gain significant advantages from effective API monitoring, as various teams can utilize specific metrics and tools tailored to their individual needs. The API metrics important to infrastructure teams will be different than what API metrics are important to API product or API platform teams. Metrics can also be dependent on where the API is in the product life cycle. An API recently launched will focus more on improving design and usage while sacrificing reliability and backwards compatibility. A team that maintains an API that’s been widely adopted by enterprise teams may focus more on driving additional feature adoption per account and give precedence to reliability and backwards compatibility over design. Additionally, as business factors change, the metrics that need to be tracked can also shift, necessitating real-time adjustments to ensure relevant insights.
In general, there are three to four teams that care about API metrics
Infrastructure/DevOps
Ensure the servers are running and limited resources are correctly allocated, potentially for multiple engineering teams.
Application Engineering/Platform
API developers are responsible for adding new features to APIs while debugging application specific issues in the API business logic. These products could be API as a Service, plugins and integrations for partners, APIs incorporated in a larger product, or something else.
Product Management
API product managers are in charge of roadmapping API features, ensuring the right API endpoints are being built, and balancing the needs of customers (whether internal or external) with engineering time and personal constraints.
Business/Growth
Business facing teams such as marketing and sales are not thinking in terms of API endpoints, rather they are mostly interested in customer adoption, ensuring they’re successfully using the APIs, where they come from, and seeing which users could be new sales opportunities.
Infrastructure API metrics
Many of these metrics are the focus of Application Performance Monitoring (APM) tools and infrastructure monitoring companies like Datadog. Specialized appliances, designed to handle the demands of real-time big data analytics, play a crucial role in efficiently managing large volumes and diverse types of data for infrastructure monitoring.
Various technologies exist to support the growing demands of real-time analytics amidst increasing digitalization. These include specialized hardware/software systems and adaptable ordinary computer systems that cater to diverse data challenges and enhance the effectiveness of infrastructure monitoring.
1: Uptime
While one of the most basic metrics, uptime or availability is the gold standard for measuring the availability of a service. Many enterprise agreements include a SLA (Service Level Agreement), and uptime is usually rolled up into that. Many times, you’ll hear terms like triple 9’s or four 9’s which is a measure of how much uptime vs downtime there is per year.
| Availability % | Downtime per year |
|---|---|
| 99% (“two nines”) | 3.65 days |
| 99.9% (“three nines”) | 8.77 hours |
| 99.99% (“four nines”) | 52.60 minutes |
| 99.999% (“five nines”) | 5.26 minutes |
Of course, going from four to five nines is far harder than going from two to three nines which is why you won’t see five nines except for the most mission critical (and expensive) of services. With that said, certain services can actually have lower uptime while ensuring graceful handling of outages without impacting your service. For example, Moesif is designed such that it can continue to collect data from our SDKs even during a full outage of the website and dashboard. Even in the worst case where our collection network is down, the SDKs will queue locally and not cause disruption of the application. Choosing the right API monitoring solution is crucial for ensuring high uptime. It allows you to evaluate various features and metrics, such as response times and performance timings, to effectively monitor APIs, especially during significant events like system migrations.
Uptime is most commonly measured via a ping service or synthetic testing such as via Pingdom or UptimeRobot. You can configure probes to run on a fixed interval such as
every minute to probe a specific endpoint such as /health or /status. This endpoint should have basic connectivity tests such as to any backing data stores or other services.
These metrics can be published on your website using tools like Statuspage.io. Moesif in fact uses an open source status page built on Lambda.
There are also more sophisticated ping services called Synthetic testing that can perform more elaborate test set ups such as running a specific sequence and asserting the response payload has a certain value. Keep in mind though synthetic testing may not be representative of real world traffic from your customers. You can have a buggy API while maintaining high uptime.
What is Synthetic Monitoring? As name implies, it is a predefined set of API calls that a server (usually by one of the providers of Monitoring services) triggers to call your service. While it doesn’t reflect the real world experience of your users, it is useful to see the sequence of these APIs as expected.
2: CPU Usage
CPU usage is one of the most classic performance metrics that can be a proxy to application responsiveness. High Server CPU usage can mean the server or virtual machine is oversubscribed and overloaded or it can mean a performance bug in your application such as too many spinlocks. Infrastructure engineers use CPU usage (along with its sister metric, memory percentage) for resource planning and measuring overall health. Certain types of applications like high bandwidth proxy services and API gateways naturally have higher CPU usage than other metrics along with workloads that involve heavy floating point math such as video encoding and machine learning workloads.
When your debugging APIs locally, you can easily see system and process CPU usage via Task manager on Windows (or Activity Monitor on Mac) to see CPU usage. On a server though,
you probably don’t want to be SSH’ing and running the top command. This is where various APM providers can be useful. APMs include an agent that you can embed in your application or on the server that captures metrics such as CPU and memory usage. It can also perform other application specific monitoring like thread profiling. Such issues, if not managed properly, can severely impact performance, but are often preventable with the right tools.
When looking at CPU usage, it’s important to look at usage per virtual CPU (i.e. physical thread). Unbalanced usage can imply applications not correctly threaded or an incorrectly sized thread pool.
Many APM providers enable you to tag an application with multiple names so you can perform rollups. For example, you may want to have a breakout of each VM metrics like my-api-westus-vm0, my-api-westus-vm1, my-api-eastus-vm0, etc while having these rolled up in a single app called my-api.
3: Memory Usage
Like CPU usage, memory usage is also a good proxy for measuring resource utilization as CPU and memory capacity are physical resources unlike a metric which may be more configuration dependent. A VM with extremely low memory usage can either be downsized or have additional services allocated to that VM to consume additional memory. On the flip side, high memory usage can be an indicator of servers overloaded. Traditionally, big data queries/stream processing and production databases consume much more memory than CPU. In fact, the size of memory per VM is a good indicator for how long your batch query can take as more memory available can reduce checkpointing, network synchronization, and paging to disk. When looking at memory usage, you should also look at the number of page faults and I/O ops. An easy mistake to make is an application that’s configured to allocate at a maximum only a small fraction of available physical memory which can cause artificially high page virtual memory thrashing.
Application API metrics
4: Request Per Minute (RPM)
RPM (Requests per Minute) is a performance metric often used when comparing HTTP or database servers. Usually, your end to end RPM will be much lower than an advertised RPM, which serves more as an upper bound for a simple “Hello World” API. Since a server will not consider latency incurred for I/O operations to databases, 3rd party services, etc. While some like to brag about their high RPM, an engineering team’s goal should be efficiency and attempt to drive this down. Certain business functions that require many API calls can be combined into fewer number of API calls to reduce this number. Common patterns like batching multiple requests in a single request can be very useful along with ensuring you have a flexible pagination scheme.
As the growing quantities of requests increase, it becomes crucial to manage these large volumes efficiently to maintain optimal RPM and ensure timely analysis.
Your RPM may vary depending on day of week or even hour per day especially if your API is geared for other businesses which exhibit lower usage during nights and weekends. There are other related terms to RPM such as RPS (Requests per Second) and QPS (Queries per Second).
5: Average and Max Latency
One of the most important metrics to track customer experience is API latency or elapsed time. Low response times are critical as they ensure immediate usability and enhance the end-user experience. While an increase in infrastructure level metrics like CPU usage may not actually correspond to a drop in user perceived responsiveness, API latency definitely will. Tracking latency by itself may not give you full understanding of why an increase occurred. It’s important to track any change on your API such as new API versions being released, new endpoints added, schema changes, and more to get to a root cause why latency increased.
Because problematic slow endpoints may be hidden when looking only at aggregate latency, it’s critical to look at breakdowns of latency by route, by geography, and other
fields to segment on. For example, you may have a POST /checkout endpoint that’s slowly been increasing in latency over time which could be due to an ever-increasing
SQL table size that’s not correctly indexed. However, due to a low volume of calls to POST /checkout, this issue is masked by your GET /items endpoint which is called far more than the checkout endpoint. Similarly, if you have a GraphQL API, you’ll want to look at the average latency per GraphQL operation.

We put latency under application/engineering even though many DevOps/Infrastructure teams will also look at latency. Usually an infrastructure person looks at aggregate latency over a set of VMs to make sure the VMs are not overloaded, but they don’t drill down into application specific metrics like per route.
6: Errors Per Minute
Similar to RPM, Errors per Minute (or error rate) is the number of API calls with non 200 family of status codes per minute and is critical for measuring how buggy and error-prone your API is. High error rates can negatively impact user experience by causing slow loading times and timeouts. In order to track errors per minute, it’s important to understand what type of errors are happening. 500 errors could imply bad things are happening with your code whereas many 400 errors could imply user errors from a poorly designed or documented API. This means when designing your API, it’s important to use the appropriate HTTP status code..
You can further drill down into seeing where these errors come from. Many 401 Unauthorized errors from one specific geo region could imply bots are attempting to hack your API.

API product metrics
APIs are no longer just an engineering term associated with microservices and SOA. APIs as a product is becoming far more common especially among B2B companies who want to one up their competition with new partners and revenue channels. API-driven companies need to look at more than just engineering metrics like errors and latency to understand how their APIs are used (or why they are not being adopted as fast as planned). Highlighting the benefit of comprehensive API product metrics can lead to faster issue resolution and enhance overall reliability.
Analytics capabilities embedded in API products allow for efficient data management and processing, making it possible to analyze large and diverse data sets effectively. This integration is vital for delivering fast and actionable insights to end-users within businesses.
The role of ensuring the right features are built lies on the API product manager, a new role that many B2B companies are rushing to fill.
7: API usage growth
For many product managers, as more users depend on APIs to run their applications, API usage (along with unique consumers) is the gold standard to measure API adoption. An API should not be just error free, but growing month over month. Unlike requests per minute, API usage should be measured in longer intervals like days or months to understand real trends. If measuring month-over-month API growth, we recommend choosing 28-days instead as it removes any bias due to weekend vs weekday usage and also differences in number of days per month. For example, February may have only 28 days whereas the month before has a full 31 days causing February to appear to have lower usage.
8: Unique API consumers
Because a month’s increase in API usage may be attributed to just a single customer account, it’s important to measure API DAU (Monthly Active Users) or unique consumers of an API. This metric can give you an overall health of new customer acquisition and growth. Many API platform teams correlate API MAU to their web MAU, to get a full product health. If web MAU is growing far faster than API MAU, then this could imply a leaky funnel during integration or implementation of a new solution. This is especially true when the core product of the company is an API such as for many B2B/SaaS companies. On the other hand, API MAU can be correlated to API usage to understand where that increased API usage came from (New vs. existing customers).
Different technologies, such as specialized appliances, processor/memory chip combinations, and in-database analytics, can significantly enhance the tracking of unique API consumers. These technologies support real-time analytics and handle large and diverse data sets, making real-time data analysis more efficient and accessible for businesses.
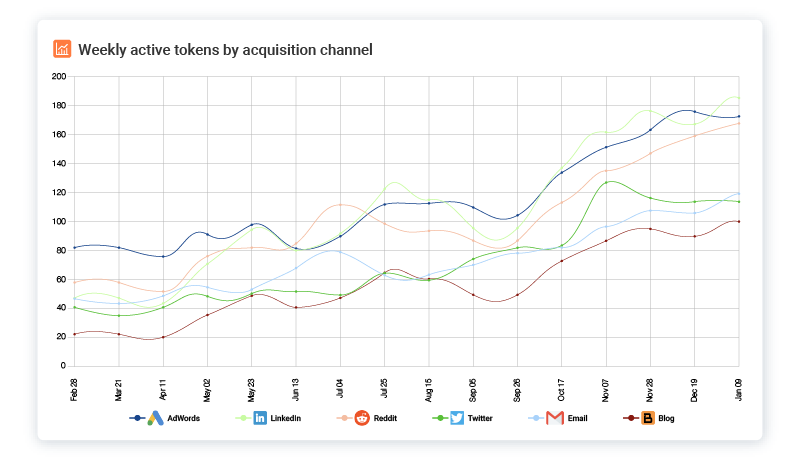
Tools like Moesif can track both individual users calling and API and also link them to companies or organizations.
9: Top customers by API usage
For any company with a focus on B2B, tracking the top API consumers can give you a huge advantage when it comes to understanding how your API is used and where upsell opportunities exist. Many experienced product leaders know that many products exhibit power law dynamics with a handful of power users having a disproportionate amount of usage compared to everyone else. Not surprisingly, these are the same power users that generally bring your company the most revenue and organic referrals.
For instance, examples of top customers and their API usage patterns can provide valuable insights. You can see how real-time analytics and specific API endpoints are utilized to enhance decision-making and customer experience management.
This means it’s critical to track what your top 10 customers are actually doing with your API. You can further break this down by what endpoints they are calling and how they’re calling them. Do they use a specific endpoint much more than your non-power users? Maybe they found their ah ha moment with your API.
10: API retention
Should you spend more money on your product and engineering or put more money into growth? Retention and churn (the opposite of retention) can tell you which path to take. A product with high product retention is closer to product market fit than a product with a churn issue. Unlike subscription retention, product retention tracks the actual usage of a product such as an API. While the two are correlated, they are not the same. In general, product churn is a leading indicator of subscription churn since customers who don’t find value in an API may be stuck with a yearly contract while not actively using the API. API retention should be higher than web retention as web retention will include customers who logged in, but didn’t necessarily integrate the platform yet. Whereas API retention looks at post-integrated customers.
Adapting business processes is crucial for improving API retention. Organizations need to evolve their operations and training to effectively incorporate real-time analytics and APIs into their workflows.
11: Time to First Hello World (TTFHW)
TTFHW is an important KPI for not just tracking your API product health, but your overall developer experience aka DX. Especially if your API is an open platform attracting 3rd party developers and partners, you want to ensure they are able to get up and running as soon as possible to their first ah ha moment. TTFHW measures how long it takes from the first visit to your landing page to an MVP integration that makes the first transaction through your API platform. This is a cross-functional metric tracking marketing, documentation and tutorials, to the API itself.
Real-time analytics applications play a crucial role in improving TTFHW by handling large data volumes efficiently, achieving high availability, and maintaining low response times. These applications adapt to changing data sources in dynamic market environments, providing immediate insights that are particularly valuable in fields like financial trading.
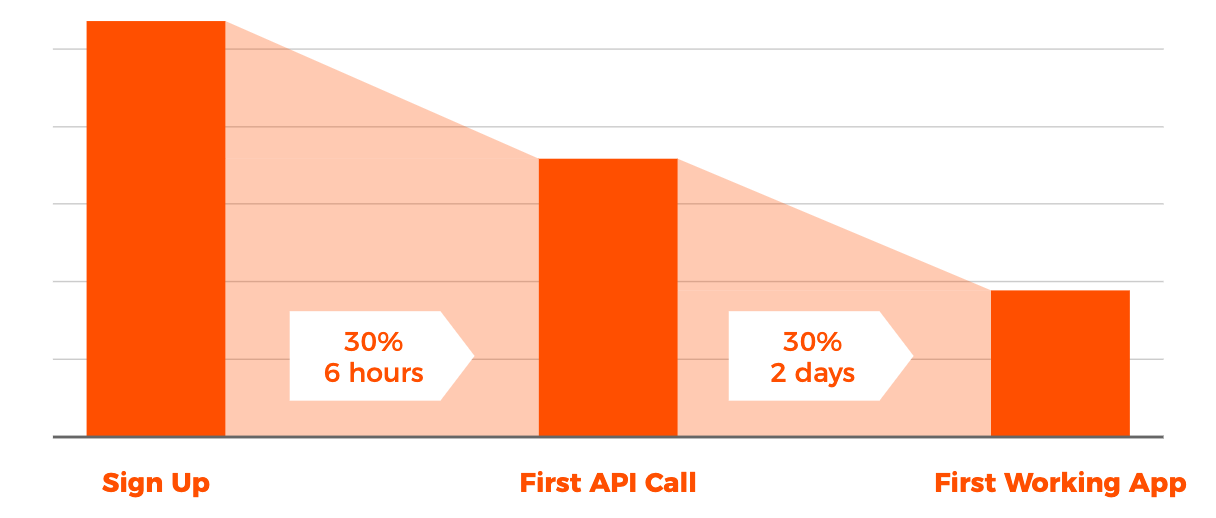
12: API Calls per business transaction
While more equals better for many product and business metrics, it’s important to keep the number of calls per business transaction as low as possible. This metric directly reflects the design of the API. If a new customer has to make 3 different calls and piece the data together, this can mean the API does not have the correct endpoints available. When designing an API, it’s important to think in terms of a business transaction or what the customer is trying to achieve rather than just features and endpoints. It may also mean your API is not flexible enough when it comes to filtering and pagination..
Additionally, managing changing data sources is crucial for optimizing API calls per business transaction. As market and business factors evolve, analytics applications must adapt to these new data inputs to maintain high availability and responsiveness in delivering insights.
13: SDK and version adoption
Many API platform teams may also have a bunch of SDKs and integrations they maintain. Unlike mobile where you just have iOS and Android as the core mobile operating systems, you may have 10’s or even hundreds of SDKs. This can become a maintenance nightmare when rolling out new features. You may selectively roll out critical features to your most popular SDKs whereas less critical features may be rolled out to less popular SDKs. Measuring API or SDK version is also important when it comes to deprecating certain endpoints and features. You wouldn’t want to deprecate the endpoint that your highest paying customer is using without some consultation on why they are using it.
Additionally, the use of internal APIs can significantly impact SDK and version adoption. Internal APIs allow for sharing functionality between components in a distributed software architecture, but they also introduce complexity in managing both internal and external APIs. Monitoring these APIs is crucial to proactively address performance issues and ensure an optimized user experience.
Business/Growth
Business/growth metrics can be similar to product metrics but focused on revenue, adoption, and customer success. For example, instead of looking at the top 10 customers by API usage, you may want to look at top 10 customers by revenue, then by their endpoint usage. For tracking business growth, analytics tools like Moesif, support enriching user profiles with customer data from your CRM or other analytics services to have a better idea who your API users are, which can inform critical buying and selling decisions.
Real-time big data analytics in financial trading can significantly impact business growth by providing timely insights that drive immediate decision-making in dynamic market conditions.
Conclusion:
For anyone building and working with APIs, it’s critical to track the correct API metrics to understand the benefits of monitoring and improving performance. Most companies would not launch a new web or mobile product without having the correct instrumentation for engineering and product. Similarly, you wouldn’t want to launch a new API without a way to instrument and track the correct API metrics. Understanding metric values is essential for establishing service level objectives (SLOs) and guiding decisions related to system design, operational priorities, and resource allocation. Sometimes the KPIs for one team can blend into another team as we saw with the API usage metrics. There can be different ways of looking at the same underlying metric. However, teams should stay focused on looking at the right metrics for their team. For example, product managers shouldn’t worry about CPU usage just like infrastructure teams shouldn’t worry about API retention. Tools like Moesif API Analytics can help you get started measuring these metrics with just a quick SDK installation.
For more API Analytics, see Chapter 1 of this series: Mastering API Analytics - the Developer Funnel
Continue with Part 2 of this series: Mastering API Analytics - Cohort Retention Analytics

Related Articles

API Analytics and Monitoring
Monitoring MCP Security and Agent Behavior with Moesif
Monitor MCP server security and agent behavior with Moesif. Detect misuse, set alerts, and gain visibility into Model Context Protocol traffic.

API Strategy
Monetizing MCP (Model Context Protocol) Servers with Moesif
Learn how to monetize MCP server usage with Moesif. Track tool calls, enforce usage-based pricing, and meter agent access with full visibility.

API Development
Using Moesif for API Observability and Analytics in NGINX One
Enable API observability in NGINX One with Moesif to track latency, errors, and usage patterns through powerful API analytics and user-aware monitoring.

Podcasts
APIs Over IPAs 19: API Product Management with Emmanuel Paraskakis, Level 250
In this episode, Emmanuel Paraskakis of Level 250 joins to discuss the role and responsibilities of API product managers.